Les données¶
Travailler avec des données est assez facile en Python. Le module pandas permet de manipuler des grandes bases de données facilement.
[1]:
import pandas as pd
Les dictionnaires¶
Supposons que nous avons deux listes. L’une contient des noms de pays,
[2]:
countries = ['Canada','United States','Germany','France','Italy']
L’autre contient la population de chacun des pays, trouvé ici
[3]:
pop = [38.068,332.915,83.9,64.426,60.367]
On aimerait pouvoir travailler avec ces données, obtenir la population du Pays en invoquant son nom, etc. Une base de donnée pandas, c’est-à-dire un dataframe n’est rien d’autre qu’un objet qui est crée autour d’un type de données en Python, le dictionnaire. Voyons voir ce qu’est un dictionnaire en le déclarant basé sur deux listes jumelées en utilisant zip:
[4]:
map_pop = dict(zip(countries,pop))
Maintenant, on veut obtenir la population de l’Allemagne. On n’a qu’à l’invoquer:
[5]:
map_pop['Germany']
[5]:
83.9
Un dictionnaire est composé d’une clé et d’items. Voyons voir
[7]:
map_pop.keys()
[7]:
dict_keys(['Canada', 'United States', 'Germany', 'France', 'Italy'])
[8]:
map_pop.values()
[8]:
dict_values([38.068, 332.915, 83.9, 64.426, 60.367])
[9]:
map_pop.items()
[9]:
dict_items([('Canada', 38.068), ('United States', 332.915), ('Germany', 83.9), ('France', 64.426), ('Italy', 60.367)])
On peut aussi composer le dictionnaire de la façon suivante:
[12]:
map_pop2 = {'Canada':38.068,'United States':332.815,'Germany':83.9,'France':64.426,'Italy':60.367}
[13]:
map_pop2['Germany']
[13]:
83.9
DataFrame¶
Un dataframe est construit autour d’un dictionnaire sur des listes (ou arrays). Par exemple,
[24]:
df = pd.DataFrame({'country':countries,'population':pop})
[25]:
df
[25]:
| country | population | |
|---|---|---|
| 0 | Canada | 38.068 |
| 1 | United States | 332.915 |
| 2 | Germany | 83.900 |
| 3 | France | 64.426 |
| 4 | Italy | 60.367 |
On peut aussi créer en utilisant
[26]:
df2 = pd.DataFrame(index=countries,columns=['population'],data=pop)
[27]:
df2
[27]:
| population | |
|---|---|
| Canada | 38.068 |
| United States | 332.915 |
| Germany | 83.900 |
| France | 64.426 |
| Italy | 60.367 |
Il y a une différence entre les deux dataframe. Le premier a deux colonnes, country et pop. Il a une colonne en gras qui débute par zéro et qui semble indiqué le numéro de l’observation. Le deuxième n’a pas la variable country mais a plutôt cette colonne qui est en gras and les noms de pays. Cette colonne en gras est l’index. L’avantage de l’index est qu’il me permet d’obtenir la valeur pour un pays plus facilement que si j’avais utilisé la colonne country.
[30]:
df2.loc['Germany','population']
[30]:
83.9
Il n’y a qu’un seul élément, donc c’est un scalaire.
Supossons que je veux deux pays,
[32]:
df2.loc[['Germany','Italy'],'population']
[32]:
Germany 83.900
Italy 60.367
Name: population, dtype: float64
Le résultat n’est pas un scalaire, mais plutôt ce qu’on appelle une Series de Pandas, puisque c’est seulement une colonne.
Je peux faire un sort sur mon index.
[34]:
df2.sort_index()
[34]:
| population | |
|---|---|
| Canada | 38.068 |
| France | 64.426 |
| Germany | 83.900 |
| Italy | 60.367 |
| United States | 332.915 |
Je peux rajouter une variable, le PIB de chaque pays, en milliards
df2
[39]:
gdp = [1711.39,20494.1,4000.39,2775.25,2072.2]
[40]:
df2['gdp'] = gdp
[41]:
df2
[41]:
| population | gdp | |
|---|---|---|
| Canada | 38.068 | 1711.39 |
| United States | 332.915 | 20494.10 |
| Germany | 83.900 | 4000.39 |
| France | 64.426 | 2775.25 |
| Italy | 60.367 | 2072.20 |
Les fonctions¶
Un paquet de statistiques sont disponible sous pandas
[45]:
df2.mean()
[45]:
population 115.9352
gdp 6210.6660
dtype: float64
[46]:
df2.sum()
[46]:
population 579.676
gdp 31053.330
dtype: float64
[47]:
df2.describe()
[47]:
| population | gdp | |
|---|---|---|
| count | 5.000000 | 5.000000 |
| mean | 115.935200 | 6210.666000 |
| std | 122.383425 | 8032.345163 |
| min | 38.068000 | 1711.390000 |
| 25% | 60.367000 | 2072.200000 |
| 50% | 64.426000 | 2775.250000 |
| 75% | 83.900000 | 4000.390000 |
| max | 332.915000 | 20494.100000 |
On peut transposer le dernier tableau
[48]:
df2.describe().transpose()
[48]:
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| population | 5.0 | 115.9352 | 122.383425 | 38.068 | 60.367 | 64.426 | 83.90 | 332.915 |
| gdp | 5.0 | 6210.6660 | 8032.345163 | 1711.390 | 2072.200 | 2775.250 | 4000.39 | 20494.100 |
Les calculs sur les colonnes¶
Le nom des colonnes se trouve dans
[49]:
df2.columns
[49]:
Index(['population', 'gdp'], dtype='object')
Calculons le PIB par habitant
[51]:
df2['gdp_per_cap'] = df2['gdp']*1e3/df2['population']
[52]:
df2
[52]:
| population | gdp | gdp_per_cap | |
|---|---|---|---|
| Canada | 38.068 | 1711.39 | 44956.131134 |
| United States | 332.915 | 20494.10 | 61559.557244 |
| Germany | 83.900 | 4000.39 | 47680.452920 |
| France | 64.426 | 2775.25 | 43076.552944 |
| Italy | 60.367 | 2072.20 | 34326.701675 |
On peut classer sur la base du PIB per capita
[56]:
df2.sort_values(by='gdp_per_cap',ascending=False)
[56]:
| population | gdp | gdp_per_cap | |
|---|---|---|---|
| United States | 332.915 | 20494.10 | 61559.557244 |
| Germany | 83.900 | 4000.39 | 47680.452920 |
| Canada | 38.068 | 1711.39 | 44956.131134 |
| France | 64.426 | 2775.25 | 43076.552944 |
| Italy | 60.367 | 2072.20 | 34326.701675 |
On peut référer aux colonnes en utilisant deux notations
[58]:
df2.gdp_per_cap
[58]:
Canada 44956.131134
United States 61559.557244
Germany 47680.452920
France 43076.552944
Italy 34326.701675
Name: gdp_per_cap, dtype: float64
[59]:
df2['gdp_per_cap']
[59]:
Canada 44956.131134
United States 61559.557244
Germany 47680.452920
France 43076.552944
Italy 34326.701675
Name: gdp_per_cap, dtype: float64
Une nouvelle colonne doit être crée par la dernière notation.
Merge¶
Supposons une autre base de donnée qui contient le continent des pays
[74]:
df3 = pd.DataFrame(index=countries,columns=['continent'],data=['North America','North America','Europe','Europe','Europe'])
[75]:
df3
[75]:
| continent | |
|---|---|
| Canada | North America |
| United States | North America |
| Germany | Europe |
| France | Europe |
| Italy | Europe |
On peut joindre ces données dans notre première base de donnée
[77]:
df4 = df2.merge(df3,left_index=True,right_index=True)
[78]:
df4
[78]:
| population | gdp | gdp_per_cap | continent | |
|---|---|---|---|---|
| Canada | 38.068 | 1711.39 | 44956.131134 | North America |
| United States | 332.915 | 20494.10 | 61559.557244 | North America |
| Germany | 83.900 | 4000.39 | 47680.452920 | Europe |
| France | 64.426 | 2775.25 | 43076.552944 | Europe |
| Italy | 60.367 | 2072.20 | 34326.701675 | Europe |
Les graphiques¶
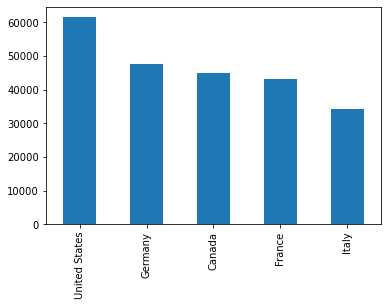
On peut faire des graphiques directement à partir d’un objet pandas!
[64]:
df2['gdp_per_cap'].sort_values(ascending=False).plot.bar()
[64]:
<AxesSubplot:>
Sauvegarde et exportation¶
Plusieurs formats sont possibles. Notons Excel, Stata, LaTex, etc. Le format natif Python, qui est très efficace est pickle (pkl).
[65]:
df2.to_excel('countries.xlsx')
Lecture de données¶
On peut télécharger des données de plus types directement, même du web. Voyons cet exemple célèbre d’ne basee de donnée sur les films (Kaggle IMDB Scores data)
[66]:
url = 'https://dq-blog-files.s3.amazonaws.com/movies.xls'
[68]:
df = pd.read_excel(url)
Il y a beaucoup de films…
[70]:
len(df)
[70]:
1338
Regardons les premiers films
[72]:
df.head()
[72]:
| Title | Year | Genres | Language | Country | Content Rating | Duration | Aspect Ratio | Budget | Gross Earnings | ... | Facebook Likes - Actor 1 | Facebook Likes - Actor 2 | Facebook Likes - Actor 3 | Facebook Likes - cast Total | Facebook likes - Movie | Facenumber in posters | User Votes | Reviews by Users | Reviews by Crtiics | IMDB Score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Intolerance: Love's Struggle Throughout the Ages | 1916 | Drama|History|War | NaN | USA | Not Rated | 123 | 1.33 | 385907.0 | NaN | ... | 436 | 22 | 9.0 | 481 | 691 | 1 | 10718 | 88 | 69.0 | 8.0 |
| 1 | Over the Hill to the Poorhouse | 1920 | Crime|Drama | NaN | USA | NaN | 110 | 1.33 | 100000.0 | 3000000.0 | ... | 2 | 2 | 0.0 | 4 | 0 | 1 | 5 | 1 | 1.0 | 4.8 |
| 2 | The Big Parade | 1925 | Drama|Romance|War | NaN | USA | Not Rated | 151 | 1.33 | 245000.0 | NaN | ... | 81 | 12 | 6.0 | 108 | 226 | 0 | 4849 | 45 | 48.0 | 8.3 |
| 3 | Metropolis | 1927 | Drama|Sci-Fi | German | Germany | Not Rated | 145 | 1.33 | 6000000.0 | 26435.0 | ... | 136 | 23 | 18.0 | 203 | 12000 | 1 | 111841 | 413 | 260.0 | 8.3 |
| 4 | Pandora's Box | 1929 | Crime|Drama|Romance | German | Germany | Not Rated | 110 | 1.33 | NaN | 9950.0 | ... | 426 | 20 | 3.0 | 455 | 926 | 1 | 7431 | 84 | 71.0 | 8.0 |
5 rows × 25 columns
Regroupement¶
Pensons à un calcul difficile, comme le nombre de titre par genres pour les 10 genres avec le plus de titre. C’est là que pandas va faire sa magie à l’aide de la fonction groupby
[89]:
df.groupby('Genres').count()['Title'].sort_values(ascending=False).head(10)
[89]:
Genres
Drama 62
Comedy|Drama 51
Comedy 48
Comedy|Drama|Romance 46
Drama|Romance 39
Action|Adventure|Thriller 28
Crime|Drama 27
Comedy|Romance 23
Crime|Drama|Thriller 20
Comedy|Crime 17
Name: Title, dtype: int64
Regardons par pays, l’écrasante majorité vient des États-Unis
[90]:
df.groupby('Country').count()['Title'].sort_values(ascending=False).head(10)
[90]:
Country
USA 1073
UK 130
France 26
Canada 25
Australia 18
Germany 12
Italy 11
Japan 9
Spain 4
West Germany 3
Name: Title, dtype: int64
Combien en fait? 82% environ…
[93]:
co_lead = df.groupby('Country').count()['Title'].sort_values(ascending=False).head(10)
[94]:
co_lead = co_lead/co_lead.sum()
co_lead
[94]:
Country
USA 0.818459
UK 0.099161
France 0.019832
Canada 0.019069
Australia 0.013730
Germany 0.009153
Italy 0.008391
Japan 0.006865
Spain 0.003051
West Germany 0.002288
Name: Title, dtype: float64
[ ]: