Introduction
Théorie et données
Le site missingprofits.world calcule ce que perd chaque pays aux paradis fiscaux. Mais comment rapatrier ces profits? Quel effet aurait une taxe sur la richesse pour réduire les inégalités? On a besoin de la théorie pour comprendre l’effet potentiel des incitatifs. Ensuite, les données pour estimer ces effets. Les économistes Emmanuel Saez et Gabriel Zucman s’intéressent à cette question avec théorie et données.

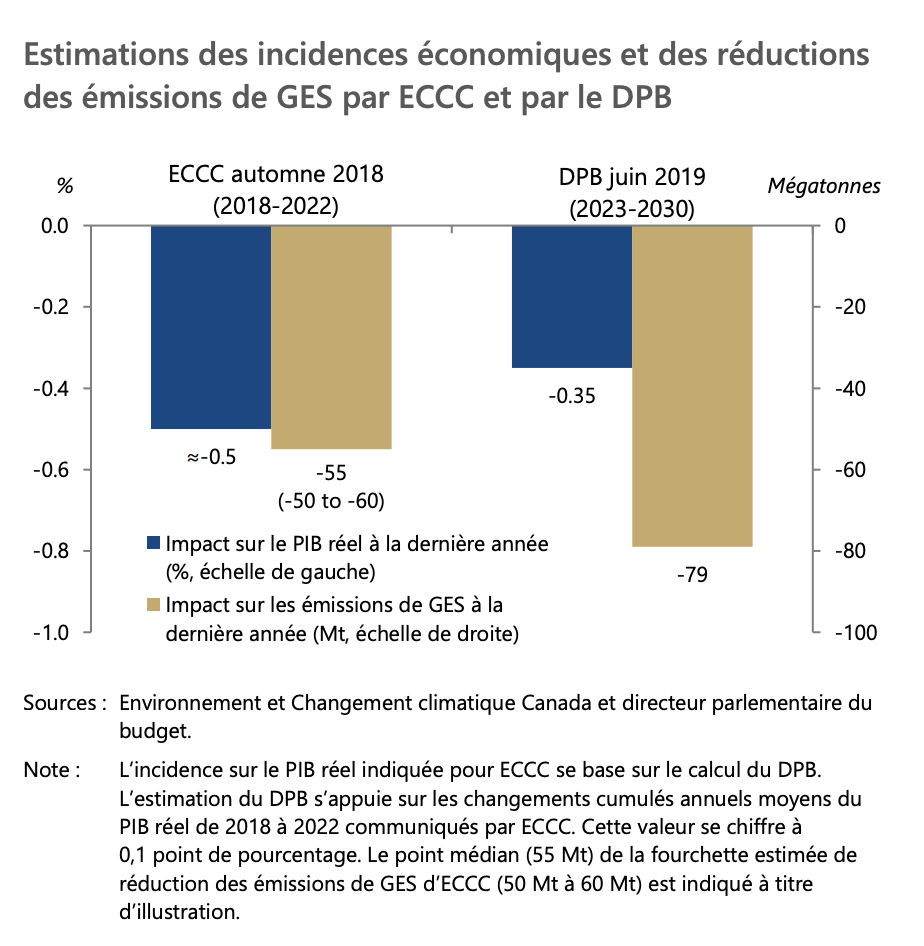
Une taxe sur le carbone pourrait être un bon moyen de lutter contre le réchauffement climatique. Mais quels sont les effets d’une telle taxe sur l’économie? En 2019, le Directeur parlementaire du Budget du Canada dans un rapport utilise un modèle d’équilibre général pour calculer ces effets. Le modèle utilise données et théorie.
Comment structurer le marché de la publicité sur internet? Quel est le prix de l’information? Comment rémunérer le classement dans les moteurs de recherche? Hal Varian est l’économiste en chef chez Google. Il est l’auteur d’un livre de théorie très populaire en microéconomie, mais aussi quelqu’un qui conjugue au quotidien données et théorie pour aider les entreprises de la nouvelle économie. Voir cette entrevue avec lui.

Les données sont partout. La théorie aide à en faire du sens:
Comprendre les comportements (e.g. tester des théories)
Quantifier des effets pour porter des jugements sur des politiques
Tarification et optimisation en entreprise
Voir aussi
Cet article de Judea Pearl, pourtant un des pionniers de l’intelligence articifielle, met en garde contre une utilisation des données sans cadre théorique.
Voir cette entrevue avec John List, de l’Université de Chicago sur l’importance des données pour les entreprises mais aussi la nécessité d’avoir des gens qui peuvent les interpréter et les utiliser.
Les modèles économiques ont plusieurs hypothèses. Les modèles simples sont utiles et permettent de bien comprendre des mécanismes comportementaux. Mais les prédictions ne devraient pas dépendre d’hypothèses qui se sont pas réalistes. Les bons théoriciens réussissent à réduire une interaction économique complexe à seulement quelques hypothèses cruciales, néamoins réalistes. Robert Solow exprime ceci merveilleusement:
« All theory depends on assumptions which are not quite true. That is what makes it theory. The art of successful theorizing is to make the inevitable simplifying assumptions in such a way that the final results are not very sensitive. A crucial assumption is one on which the conclusions do depend sensitively, and it is important that crucial assumptions be reasonably realistic. When the results of a theory seem to flow specifically from a special crucial assumption, then if the assumption is dubious, the results are suspect. » (A Contribution to the Theory of Economic Growth, QJE 1956)
Rappel mathématique
Les mathématiques sont essentielles, en particulier le calcul différentiel, afin d’analyser le comportement, mesurer l’effet de changements dans l’environnement (prix, taxes). Voici un (rappel) des concepts qui sont importants pour le cours.
L’analyse marginale et les approximations
Comment décrire une fonction \(f(X)\)?
Fonctions généralement compliquées, fonctions linéaires simples… En python, voici comment écrire une fonction.
def f(x):
return x**2
def g(x):
return 1/x
Localement, on peut faire une approximation de toute fonction pour \(X\) près de \(X_0\):
\[f(X) \simeq f(X_0) + \alpha (X-X_0)\]
Voici une approximation, pour un \(\alpha\) donné:
def fa(x,x0,alpha):
return f(x0) + alpha * (x - x0)
Pour trouver le meilleur \(\alpha\), on a que pour \(X\) près de \(X_0\)
En python,
x = 2
x0 = 1
alpha = (f(x) - f(x0))/(x-x0)
Bien sur, on triche par on calcule la fonction à \(f(x)\)! Comment faire sans calculer cette valeur?
Utilisons ce concept de pente à un point, mais regardons une distance plus petite. En fait, minuscule.
Donc, on peut définir
On peut toujours calculer une dérivée numériquement en utilisant un \(\epsilon\) petit:
def fp(x0):
eps = 1e-6
return (f(x0+eps) - f(x0))/eps
et alors, l’approximation devient
En python, on peut écrire
def fa(x,x0):
return f(x0) + fp(x0)*(x-x0)
Si on veut prédire le changement dans la valeur d’une fonction, la dérivée est donc très utile! Pour plusieurs types de fonctions, on peut trouver l’expression de la dérivée sans faire un calcul numérique…
Bien sur, la dérivée nous donne une direction locale. Donc, l’approximation linéaire locale peut être une bonne approximation (pour une ligne par exemple) mais peut-être moins précise quand la fonction n’est pas linéaire. Ainsi, on en arrive à la règle suivante pour les approximations.
Important
Une approximation est plus précise quand la distance \(\epsilon = X - X_0\) est petite.
À faire
Voir la dérivée à la limite sur le site EconGraph.org
La dérivée
Voici des recettes:
Avec des constantes
\(f(X) = b + aX\): \(f'(X) = a\)
\(f(X) = \log X\): \(f'(X) = \frac{1}{X}\)
\(f(X) = e^{aX}\): \(f'(X) = ae^{aX}\)
\(f(X) = X^a\): \(f'(X) = a X^{a-1}\)
Avec des fonctions
Règle du produit: \(f(X) = a(X)b(X)\), \(f'(X) = a'(X)b(X) + a(X)b'(X)\)
Règle du quotient: \(f(X) = \frac{a(X)}{b(X)}\), \(f'(X) = \frac{a'(X)b(X) - a(X)b'(X)}{b(X)^2}\)
Règle de chaine: \(f(X) = a(b(X))\), \(f'(X) = a'(b(X))b'(X)\)
Règle d’addition (et soustraction): \(f(X) = a(X) + b(X)\), \(f'(X) = a'(X) + b'(X)\).
À faire
Exercice A: Trouvez les dérivées de \(f(X)=\sqrt{X},\frac{X}{1+X},\frac{1}{2}X^2 + 2X-10,(1+\frac{X}{2})^2\).
À faire
Voir la représentation graphique d’une dérivée EconGraph.org
Approximations d’ordres supérieurs
Si la fonction a des dérivées supérieures non nulles, ou bien \(X\) est loin de \(X_0\), l’approximation de premier ordre que nous avons vu produira une approximation assez mauvaise… Par ailleurs, on veut peut-être aussi caractériser des fonctions par autre chose que seulement leur pente. (est-ce une courbe, etc?).
On peut pousser plus loin le concept d’approximation,
Polynome d’ordre 2 devrait être meilleur…
Alors, on approxime par deuxième ordre
Polynome d’ordre \(k\): on peut certainement généraliser.
Ce type d’approximation est appelée approximation de Taylor. On utilise alors les dérivées d’ordres supérieurs d’une fonction:
On dénote \(f'(X), f''(X)\) ou \(\frac{d f}{d X},\frac{d}{d X}(\frac{d f}{d X}) = \frac{d^2 f}{d X^2}\).
Concavité et Convexité des fonctions
Une fonction est concave si pour tout point \((X_1,X_2)\) et tout \(0<\lambda<1\):
et convexe si faux. On dit strictement concave (ou convexe) si les inégalités sont strictes (n’incluent pas zéro).
À faire
Exercice B: Montrer ceci graphiquement pour une fonction concave.
Note
En d’autres termes, si pour toutes les pairs de points, la ligne qui les rejoints est en dessous de la fonction, la fonction est concave. Si c’est l’opposé, elle est convexe.
Approximation et maximum (minimum)
Considérons l’approximation de premier ordre
Observons que:
Si \(f'(X_0)>0\) un petit changement \(\Delta X>0\) augmente \(f\)
Si \(f'(X_0) <0\) un petit changement \(\Delta X <0\) augmente \(f\)
Si \(X_0\) est la solution de \(\max_X f(X)\), il faut que \(f'(X_0) =0\)! C’est la condition de premier ordre (CPO) nécessaire.
Considérons l’approximation de deuxième ordre pour voir si elle est suffisante:
Pour un maximum (local), il faut que \(f'(X_0)=0\) (condition de premier ordre, CPO) et \(f''(X_0)<0\) (condition de deuxième ordre, CDO). Observons que:
Si \(f'(X_0) = 0\), mais \(f''(X_0)>0\), alors \(f(X_0+\Delta X) > f(X_0)\).
f’(X) doit être positif quand \(\Delta X <0\) et négatif quand \(\Delta X>0\).
Avertissement
La condition de premier ordre est nécessaire mais n’est pas suffisante. Une fonction qui a un point d’inflection, aura une CPO respectée sur le point de scelle sans pour autant que ce point soit un maximum. La CDO prévient de cas de figure.
À faire
Exercice C: Trouvez l’optimum de la fonction \(f(X) = X(10-X)\).
À faire
Voir un exemple graphique d’un maximum global EconGraph.org
Dérivée partielle
Supposons la fonction \(f(X,Y)\). La dérivée partielle se fait en gardant fixes (ou exogènes) les autres variables: \(f'_X(X,Y) = \frac{\partial f(X,Y)}{\partial X}\).
Note
Une dérivée partielle ne représente donc pas de difficulté additionelle. On peut revoir le cas de figure ici-haut, \(f(X) = aX\) comme étant \(g(X,a) = a X\) et donc \(g'_X(x,a) = f'(X) = a\).
La différentielle totale
Parfois, il est utile de regarder les combinaisons de \((X,Y)\) telles que \(f(X,Y) = \overline{f}\), i.e. la fonction donne la même valeur d’output. Ces combinaisons peuvent être trouvées en inversant la fonction: en isolant \(Y=g(X,\overline{f})\). Par exemple, considérons \(f(X,Y) = \log(X) + \log(Y)\). Fixons \(f(X,Y)=10\). Alors on peut trouver les combinaisons par \(Y = \exp(10 -\log(X))\). Mais on peut aussi décrire ces combinaisons en utilisant la différentielle totale (une approximation linéaire).
On peut toujours décrire la forme d’une fonction à un point donné par:
L’opérateur d dénote un changement. Si on pose \(df(X,Y)=0\), on peut réarranger pour obtenir
On qualifie la dérivée par l’indice \(df=0\) pour indiquer que c’est une dérivée obtenue en contraignant la valeur de la fonction à être constante.
À faire
Exercice D: Trouvez \(\frac{dY}{dX}\Bigr|_{df=0}\) par différentielle totale pour \(f(X,Y)=\log(XY)\).
Homogénéité d’une fonction
La dérivée partielle informe sur le comportement de la fonction quand un des arguments varie alors que les autres demeurent constants. Mais on pourrait aussi s’intéresser au comportement d’une fonction quand tous les arguments augmentent (ou diminuent) d’une même proportion. On utilise le concept d’homogénéité. Il y a deux façons de s’y prendre:
Approche directe: Une fonction est homogène de degré \(r\) si pour tout \(\lambda>0\),
Théorème d’Euler: Si une fonction est homogène de degré \(r\), alors:
À faire
Exercice E: Trouvez le degré d’homogénéité de la fonction \(f(X,Y)=X^\alpha Y^\beta\) des deux façons.
Approximation et maximum
On a besoin d’autant de CPO qu’il y a de variables de contrôle. Les conditions nécessaires sont
pour une fonction \(f(X,Y)\). La condition de deuxième ordre est plus compliquée et nous n’allons pas la couvrir.
Maximisation avec contrainte
Un problème contraint prend la forme:
Le lagrangien
La méthode de Lagrange consiste à résoudre pour \((X,Y)\),
où \(\lambda\) est un multiplicateur de Lagrange.
Ces trois équations sont les CPO du lagrangien:
Le lagrangien \(L(X,Y,\lambda)\) est une fonction objective modifiée qui permet de pénaliser un écart de la contrainte (pour s’assurer qu’elle soit respectée). On remarque que si \(\lambda = 0\), on a les deux CPO non-contraintes \(f'_X(X,Y)=0\) et \(f'_Y(X,Y)=0\) qui donnent une solution optimale sans avoir besoin de la troisième. Seulement si la contrainte est mordante (si \(\lambda \neq 0\)) aurons-nous une solution différente…
À faire
Exercice F: Maximisez la fonction \(f(X,Y) = \log X + \log Y\) sous la contrainte \(X+Y \le m\) par la méthode du lagrangien.
Note sur les logarithmes
Note
Dans les notes, nous utiliserons \(\log\) en base \(e=2.718281828459\) et non en base 10. Donc, il s’agit du logarithme naturel (\(\ln = \log_e\)). Python utilise aussi la base exponentielle.
Introduction à Python
Ce premier notebook devrait s’ouvrir sur Google Colab et vous permettre de faire vos début sur Python.
![]()
Vous pouvez aussi consulter ce site pour davantage de matériel d’introduction sur Python.